Linkage disequilibrium
In population genetics, linkage disequilibrium is the non-random association of alleles at two or more loci, not necessarily on the same chromosome. It is also referred to as to as gametic phase disequilibrium [1], or simply gametic disequilibrium. In other words, linkage disequilibrium is the occurrence of some combinations of alleles or genetic markers in a population more often or less often than would be expected from a random formation of haplotypes from alleles based on their frequencies. It is not the same as linkage, which is the association of two or more loci on a chromosome with limited recombination between them. The amount of linkage disequilibrium depends on the difference between observed and expected (assuming random distributions) allelic frequencies.
The level of linkage disequilibrium is influenced by a number of factors, including genetic linkage, selection, the rate of recombination, the rate of mutation, genetic drift, non-random mating, and population structure. A limiting example of the effect of rate of recombination may be seen in some organisms (such as bacteria) that reproduce asexually and hence exhibit no recombination to break down the linkage disequilibrium. An example of the effect of population structure is the phenomenon of Finnish disease heritage, which is attributed to a population bottleneck.
Contents |
Definition
Consider the haplotypes for two loci A and B with two alleles each—a two-locus, two-allele model. Then the following table defines the frequencies of each combination:
| Haplotype | Frequency |
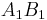 |
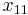 |
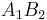 |
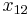 |
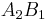 |
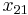 |
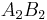 |
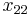 |
Note that these are relative frequencies. One can use the above frequencies to determine the frequency of each of the alleles:
| Allele | Frequency |
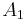 |
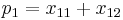 |
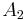 |
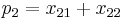 |
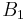 |
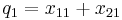 |
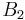 |
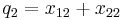 |
If the two loci and the alleles are independent from each other, then one can express the observation as " is found and is found". The table above lists the frequencies for , 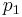 , and for,
, and for, 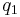 , hence the frequency of is , and according to the rules of elementary statistics
, hence the frequency of is , and according to the rules of elementary statistics 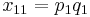 .
.
The deviation of the observed frequency of a haplotype from the expected is a quantity[2] called the linkage disequilibrium[3] and is commonly denoted by a capital D:
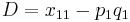 |
In the genetic literature the phrase "two alleles are in LD" usually means that D ≠ 0. Contrariwise, "linkage equilibrium" means D = 0.
The following table illustrates the relationship between the haplotype frequencies and allele frequencies and D.
|
|
Total | |
|
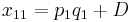 |
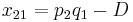 |
|
|
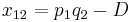 |
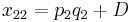 |
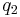 |
| Total | |
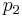 |
 |
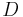 is easy to calculate with, but has the disadvantage of depending on the frequencies of the alleles. This is evident since frequencies are between 0 and 1. If any locus has an allele frequency 0 or 1 no disequilibrium can be observed. When the allelic frequencies are 0.5, the disequilibrium is maximal. Lewontin[4] suggested normalising D by dividing it by the theoretical maximum for the observed allele frequencies. Thus
is easy to calculate with, but has the disadvantage of depending on the frequencies of the alleles. This is evident since frequencies are between 0 and 1. If any locus has an allele frequency 0 or 1 no disequilibrium can be observed. When the allelic frequencies are 0.5, the disequilibrium is maximal. Lewontin[4] suggested normalising D by dividing it by the theoretical maximum for the observed allele frequencies. Thus 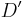 =
= 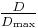 where
where 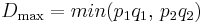 when
when  , and
, and 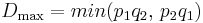 when
when 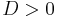 .
.
Another measure of LD which is an alternative to is the correlation coefficient between pairs of loci, expressed as 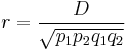 . This is also adjusted to the loci having different allele frequencies.
. This is also adjusted to the loci having different allele frequencies.
In summary, linkage disequilibrium reflects the difference between the expected haplotype frequencies under the assumption of independence, and observed haplotype frequencies. A value of 0 for indicates that the examined loci are in fact independent of one another, while a value of 1 demonstrates complete dependency.
Role of recombination
In the absence of evolutionary forces other than random mating and Mendelian segregation, the linkage disequilibrium measure converges to zero along the time axis at a rate depending on the magnitude of the recombination rate 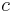 between the two loci.
between the two loci.
Using the notation above, , we can demonstrate this convergence to zero as follows. In the next generation, 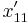 , the frequency of the haplotype , becomes
, the frequency of the haplotype , becomes
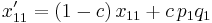 |
This follows because a fraction 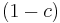 of the haplotypes in the offspring have not recombined, and are thus copies of a random haplotype in their parents. A fraction of those are . A fraction have recombined these two loci. If the parents result from random mating, the probability of the copy at locus
of the haplotypes in the offspring have not recombined, and are thus copies of a random haplotype in their parents. A fraction of those are . A fraction have recombined these two loci. If the parents result from random mating, the probability of the copy at locus  having allele is and the probability of the copy at locus
having allele is and the probability of the copy at locus 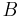 having allele is , and as these copies are initially on different loci, these are independent events so that the probabilities can be multiplied.
having allele is , and as these copies are initially on different loci, these are independent events so that the probabilities can be multiplied.
This formula can be rewritten as
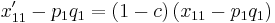 |
so that
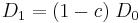 |
where at the  -th generation is designated as
-th generation is designated as 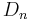 . Thus we have
. Thus we have
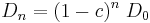 . . |
If 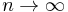 , then
, then 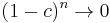 so that converges to zero.
so that converges to zero.
If at some time we observe linkage disequilibrium, it will disappear in the future due to recombination. However, the smaller the distance between the two loci, the smaller will be the rate of convergence of to zero.
Example: Human Leukocyte Antigen (HLA) alleles
HLA constitutes a group of cell surface antigens as MHC of humans. Because HLA genes are located at adjacent loci on the particular region of a chromosome and presumed to exhibit epistasis with each other or with other genes, a sizable fraction of alleles are in linkage disequilibrium.
An example of such linkage disequilibrium is between HLA-A1 and B8 alleles in unrelated Danes[5] referred to by Vogel and Motulsky (1997).[6]
| Antigen j | Total | ||||
|---|---|---|---|---|---|
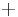 |
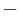 |
||||
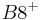 |
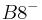 |
||||
| Antigen i | |
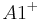 |
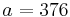 |
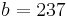 |
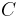 |
|
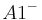 |
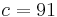 |
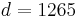 |
|
|
| Total | |
|
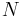 |
||
| No. of individuals | |||||
Because HLA is codominant and HLA expression is only tested locus by locus in surveys, LD measure is to be estimated from such a 2x2 table to the right.[6][7][8][9]
expression () frequency of antigen  :
:
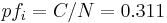 ;
;
expression () frequency of antigen 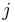 :
:
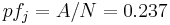 ;
;
frequency of gene :
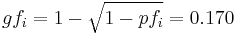 ,
,
and
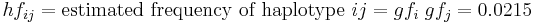 .
.
Denoting the '―' alleles at antigen i to be 'x,' and at antigen j to be 'y,' the observed frequency of haplotype xy is
![o[hf_{xy}]=\sqrt{d/N}](/2012-wikipedia_en_all_nopic_01_2012/I/1bac0b997118a0a1a88c724f015eb770.png)
and the estimated frequency of haplotype xy is
![e[hf_{xy}]=\sqrt{(D/N)(B/N)}](/2012-wikipedia_en_all_nopic_01_2012/I/91ddb326cdaec8f509cd491e844bdb2f.png) .
.
Then LD measure 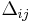 is expressed as
is expressed as
![\Delta_{ij}=o[hf_{xy}]-e[hf_{xy}]=\frac{\sqrt{Nd}-\sqrt{BD}}{N}=0.0769](/2012-wikipedia_en_all_nopic_01_2012/I/20a9e461731aefbcc952833c8ef8f306.png) .
.
Standard errors 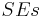 are obtained as follows:
are obtained as follows:
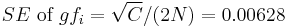 ,
,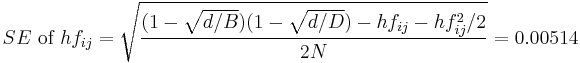
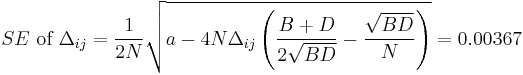 .
.
Then, if
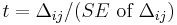
exceeds 2 in its absolute value, the magnitude of is large statistically significantly. For data in Table 1 it is 20.9, thus existence of statistically significant LD between A1 and B8 in the population is admitted.
| HLA-A alleles i | HLA-B alleles j | |
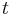 |
|---|---|---|---|
| A1 | B8 | 0.065 | 16.0 |
| A3 | B7 | 0.039 | 10.3 |
| A2 | Bw40 | 0.013 | 4.4 |
| A2 | Bw15 | 0.01 | 3.4 |
| A1 | Bw17 | 0.014 | 5.4 |
| A2 | B18 | 0.006 | 2.2 |
| A2 | Bw35 | -0.009 | -2.3 |
| A29 | B12 | 0.013 | 6.0 |
| A10 | Bw16 | 0.013 | 5.9 |
Table 2 shows some of the combinations of HLA-A and B alleles where significant LD was observed among Caucasians.[9]
Vogel and Motulsky (1997)[6] argued how long would it take that linkage disequilibrium between loci of HLA-A and B disappeared. Recombination between loci of HLA-A and B was considered to be of the order of magnitude 0.008. We will argue similarly to Vogel and Motulsky below. In case LD measure was observed to be 0.003 in Caucasians in the list of Mittal[9] it is mostly non-significant. If 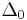 had reduced from 0.07 to 0.003 under recombination effect as shown by
had reduced from 0.07 to 0.003 under recombination effect as shown by 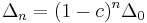 , then
, then 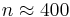 . Suppose a generation took 25 years, this means 10,000 years. The time span seems rather short in the history of humans. Thus observed linkage disequilibrium between HLA-A and B loci might indicate some sort of interactive selection.[6]
. Suppose a generation took 25 years, this means 10,000 years. The time span seems rather short in the history of humans. Thus observed linkage disequilibrium between HLA-A and B loci might indicate some sort of interactive selection.[6]
The presence of linkage disequilibrium between an HLA locus and a presumed major gene of disease susceptibility corresponds to any of the following phenomena:
- Relative risk for the person having a specific HLA allele to become suffered from a particular disease is greater than 1.[10]
- The HLA antigen frequency among patients exceeds more than that among a healthy population. This is evaluated by
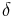 value[11] to exceed 0.
value[11] to exceed 0.
| Ankylosing spondylitis | Total | |||
|---|---|---|---|---|
| Patients | Healthy controls | |||
| HLA alleles | 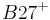 |
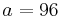 |
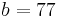 |
|
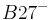 |
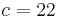 |
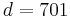 |
|
|
| Total | |
|
|
|
- 2x2 association table of patients and healthy controls with HLA alleles shows a significant deviation from the equilibrium state deduced from the marginal frequencies.
(1) Relative risk
Relative risk of an HLA allele for a disease is approximated by the odds ratio in the 2x2 association table of the allele with the disease. Table 3 shows association of HLA-B27 with ankylosing spondylitis among a Dutch population.[12] Relative risk  of this allele is approximated by
of this allele is approximated by
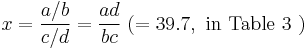 .
.
Woolf's method[13] is applied to see if there is statistical significance. Let
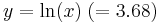
and
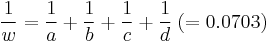 .
.
Then
![\chi^2=wy^2\;\left [=193>\chi^2(p=0.001,\; df=1)=10.8 \right ]](/2012-wikipedia_en_all_nopic_01_2012/I/388430d3c9392e03a17d8f42665f3347.png)
follows the chi-square distribution with 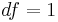 . In the data of Table 3, the significant association exists at the 0.1% level. Haldane's[14] modification applies to the case when either of
. In the data of Table 3, the significant association exists at the 0.1% level. Haldane's[14] modification applies to the case when either of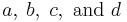 is zero, where replace and
is zero, where replace and 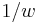 with
with
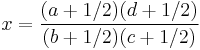
and
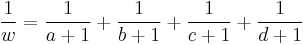 ,
,
respectively.
| Disease | HLA allele | Relative risk (%) | FAD (%) | FAP (%) | |
|---|---|---|---|---|---|
| Ankylosing spondylitis | B27 | 90 | 90 | 8 | 0.89 |
| Reiter's syndrome | B27 | 40 | 70 | 8 | 0.67 |
| Spondylitis in inflammatory bowel disease | B27 | 10 | 50 | 8 | 0.46 |
| Rheumatoid arthritis | DR4 | 6 | 70 | 30 | 0.57 |
| Systemic lupus erythematosus | DR3 | 3 | 45 | 20 | 0.31 |
| Multiple sclerosis | DR2 | 4 | 60 | 20 | 0.5 |
| Diabetes mellitus type 1 | DR4 | 6 | 75 | 30 | 0.64 |
In Table 4, some examples of association between HLA alleles and diseases are presented.[10]
(1a) Allele frequency excess among patients over controls
Even high relative risks between HLA alleles and the diseases were observed, only the magnitude of relative risk would not be able to determine the strength of association.[11] value is expressed by
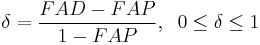 ,
,
where 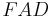 and
and 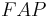 are HLA allele frequencies among patients and healthy populations, respectively.[11] In Table 4, column was added in this quotation. Putting aside 2 diseases with high relative risks both of which are also with high values, among other diseases, juvenile diabetes mellitus (type 1) has a strong association with DR4 even with a low relative risk
are HLA allele frequencies among patients and healthy populations, respectively.[11] In Table 4, column was added in this quotation. Putting aside 2 diseases with high relative risks both of which are also with high values, among other diseases, juvenile diabetes mellitus (type 1) has a strong association with DR4 even with a low relative risk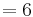 .
.
(2) Discrepancies from expected values from marginal frequencies in 2x2 association table of HLA alleles and disease
This can be confirmed by 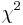 test calculating
test calculating
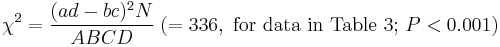 .
.
where . For data with small sample size, such as no marginal total is greater than 15 (and consequently  ), one should utilize Yates's correction for continuity or Fisher's exact test.[15]
), one should utilize Yates's correction for continuity or Fisher's exact test.[15]
Resources
A comparison of different measures of LD is provided by Devlin & Risch [16]
The International HapMap Project enables the study of LD in human populationsonline. The Ensembl project integrates HapMap data and such from dbSNP in general with other genetic information.
Analysis software
- LDHat
- Haploview
- LdCompare[17]— open-source software for calculating LD.
- PyPop
- SNP and Variation Suite- commercial software with interactive LD plot.
- GOLD - Graphical Overview of Linkage Disequilibrium
- TASSEL -software to evaluate linkage disequilibrium, traits associations, and evolutionary patterns
Simulation software
See also
- Haploview
- Hardy-Weinberg principle
- Genetic linkage
- Co-adaptation
- Genealogical DNA test
- Tag SNP
- Association Mapping
- Family based QTL mapping
References
- ^ Falconer, DS; Mackay, TFC (1996). Introduction to Quantitative Genetics (4th ed.). Harlow, Essex, UK: Addison Wesley Longman. ISBN 0-582-24302-5.
- ^ Robbins, R.B. (1 July 1918). "Some applications of mathematics to breeding problems III". Genetics 3 (4): 375–389. PMC 1200443. PMID 17245911. http://www.genetics.org/cgi/reprint/3/4/375.
- ^ R.C. Lewontin and K. Kojima (1960). "The evolutionary dynamics of complex polymorphisms". Evolution 14 (4): 458–472. doi:10.2307/2405995. ISSN 0014-3820. JSTOR 2405995.
- ^ Lewontin, R. C. (1964). "The interaction of selection and linkage. I. General considerations; heterotic models". Genetics 49 (1): 49–67. PMC 1210557. PMID 17248194. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=1210557.
- ^ a b Svejgaard A, Hauge M, Jersild C, Plaz P, Ryder LP, Staub Nielsen L, Thomsen M (1979). The HLA System: An Introductory Survey, 2nd ed. Basel; London; Chichester: Karger; Distributed by Wiley, ISBN 3805530498(pbk).
- ^ a b c d Vogel F, Motulsky AG (1997). Human Genetics : Problems and Approaches, 3rd ed.Berlin; London: Springer, ISBN 3540602909.
- ^ Mittal KK, Hasegawa T, Ting A, Mickey MR, Terasaki PI (1973). "Genetic variation in the HL-A system between Ainus, Japanese, and Caucasians," In Dausset J, Colombani J, eds. Histocompatibility Testing, 1972, pp. 187-195, Copenhagen: Munksgaard, ISBN 8716011015.
- ^ Yasuda N, Tsuji K (1975). "A counting method of maximum likelihood for estimating haplotype frequency in the HL-A system." Jinrui Idengaku Zasshi 20(1): 1-15, PMID 1237691.
- ^ a b c d Mittal KK (1976). "The HLA polymorphism and susceptibility to disease." Vox Sang 31: 161-173, PMID 969389.
- ^ a b c Gregersen PK (2009). "Genetics of rheumatic diseases," InFirestein GS, Budd RC, Harris ED Jr, McInnes IB, Ruddy S, Sergent JS, eds. (2009). Kelley's Textbook of Rheumatology, pp. 305-321, Philadelphia, PA: Saunders/Elsevier, ISBN 9781416032854.
- ^ a b c Bengtsson BO, Thomson G (1981). "Measuring the strength of associations between HLA antigens and diseases." Tissue Antigens18(5): 356-363, PMID 7344182.
- ^ a b Nijenhuis LE (1977). "Genetic considerations on association between HLA and disease." Hum Genet38(2): 175-182, PMID 908564.
- ^ Woolf B (1955). "On estimating the relation between blood group and disease." Ann Hum Genet 19(4): 251-253, PMID 14388528.
- ^ Haldane JB (1956). "The estimation and significance of the logarithm of a ratio of frequencies." Ann Hum Genet20(4): 309-311, PMID 13314400.
- ^ Sokal RR, Rohlf FJ (1981). Biometry: The Principles and Practice of Statistics in Biological Research. Oxford: W.H. Freeman, ISBN 0716712547.
- ^ Devlin B., Risch N. (1995). "A Comparison of Linkage Disequilibrium Measures for Fine-Scale Mapping". Genomics 29 (2): 311–322. doi:10.1006/geno.1995.9003. PMID 8666377. http://www.sciencedirect.com/science?_ob=MImg&_imagekey=B6WG1-45S9156-30-1&_cdi=6809&_user=128590&_orig=browse&_coverDate=09%2F30%2F1995&_sk=999709997&view=c&wchp=dGLbVtb-zSkzk&md5=71c2158ad4c51ae80b12a68c68814f78&ie=/sdarticle.pdf.
- ^ Hao K., Di X., Cawley S. (2007). "LdCompare: rapid computation of single- and multiple-marker r2 and genetic coverage". Bioinformatics 23 (2): 252–254. doi:10.1093/bioinformatics/btl574. PMID 17148510. http://bioinformatics.oxfordjournals.org/cgi/reprint/23/2/252.
Further reading
- Hedrick, Philip W. (2005). Genetics of Populations (3rd ed.). Sudbury, Boston, Toronto, London, Singapore: Jones and Bartlett Publishers. ISBN 0763747726.
- Bibliography: Linkage Disequilibrium Analysis : a bibliography of more than one thousand articles on Linkage disequilibrium published since 1918.
|
|||||||||||||||||||||||